
Comparisons of Latency across Node Service Providers in Ethereum
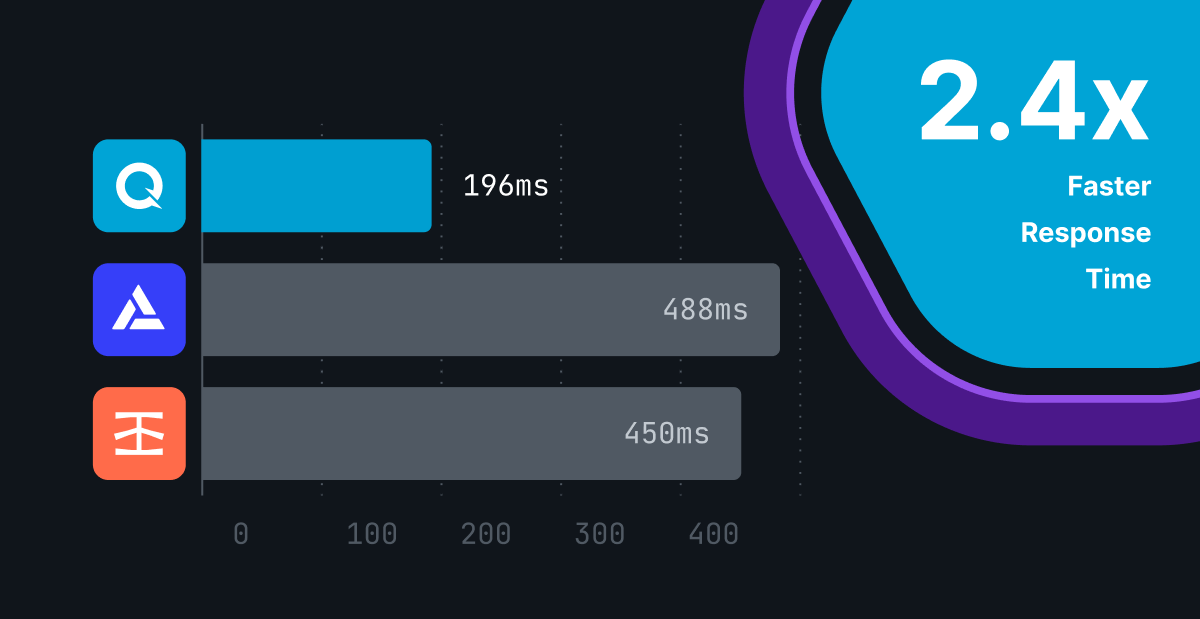
QuickNode published benchmarking study showing a 2.4x latency improvement against popular infrastructure providers, Alchemy and Infura.

Authors: Manuel Kreutz, Noah Hein
Purpose of Study
We have written about the importance of latency in a previous whitepaper, comparing QuickNode’s globally distributed API network against public endpoints in the Solana ecosystem. We received a tremendous amount of positive feedback from the community for publishing that benchmarking data and transparently showcasing our methodology.
However, many developers also commented that they expected that public endpoints would be slower as those options are frequently rate-limited. And while the secondary comparison against a competing node service provider in the Solana ecosystem was helpful, more frequently we heard that developers were interested in comparing QuickNode against other popular node service providers in the Ethereum ecosystem, where there are several popular options for developers to choose from (yet very little in the way of objective data for consumers to compare options for their hard-earned dollars). Therefore we decided to publish a second paper with this focus in mind, comparing QuickNode in a head-to-head against popular node service alternatives, Alchemy and Infura.
Recap: What is latency, and why does it matter?
As we have previously written, latency matters. One of the biggest issues standing in the way of mass consumer adoption of blockchain applications is speed. We have seen this multiple times in the Web2 space where 10 years ago, Amazon found that an incremental 100 milliseconds of latency cost them 1% of sales. And we intuitively know this each time we abandon a webpage loading on our mobile phones because the page takes too long to load.
It is natural to expect that these consumer behaviors will carry over into Web3. And as more and more blockchain builders use node service providers for consumer-facing applications, comparisons of latency across providers matters for any company hoping to scale. This is not just a nice-to-have, but a business imperative.
Defining a useful latency metric for Ethereum comparisons
Our research team wanted to structure an objective and data-driven comparison reflecting common use cases for Ethereum applications. Similar to our last whitepaper, we focused on latency (as measured by the response time, in milliseconds). Requests were made from 16 locations worldwide (across North America, Europe, and Asia) to their respective provider networks, with those requests made every minute over the test period of 28 days, and then responses to those calls were logged and measured. The average of those requests over the study period across all locations generates the headline comparison for the benchmarking.
The comparison involved two of the top five Ethereum calls (Eth_getTransactionReceipt, and eth_call). We chose these two calls because Eth_getTransactionReceipt can be cached, while eth_call cannot be cached, and we wanted to show the comparison for both in case there were any substantial differences.
Lastly, the test period ran from February 1st - February 28th, 2022. The results are compiled and presented below:
Results
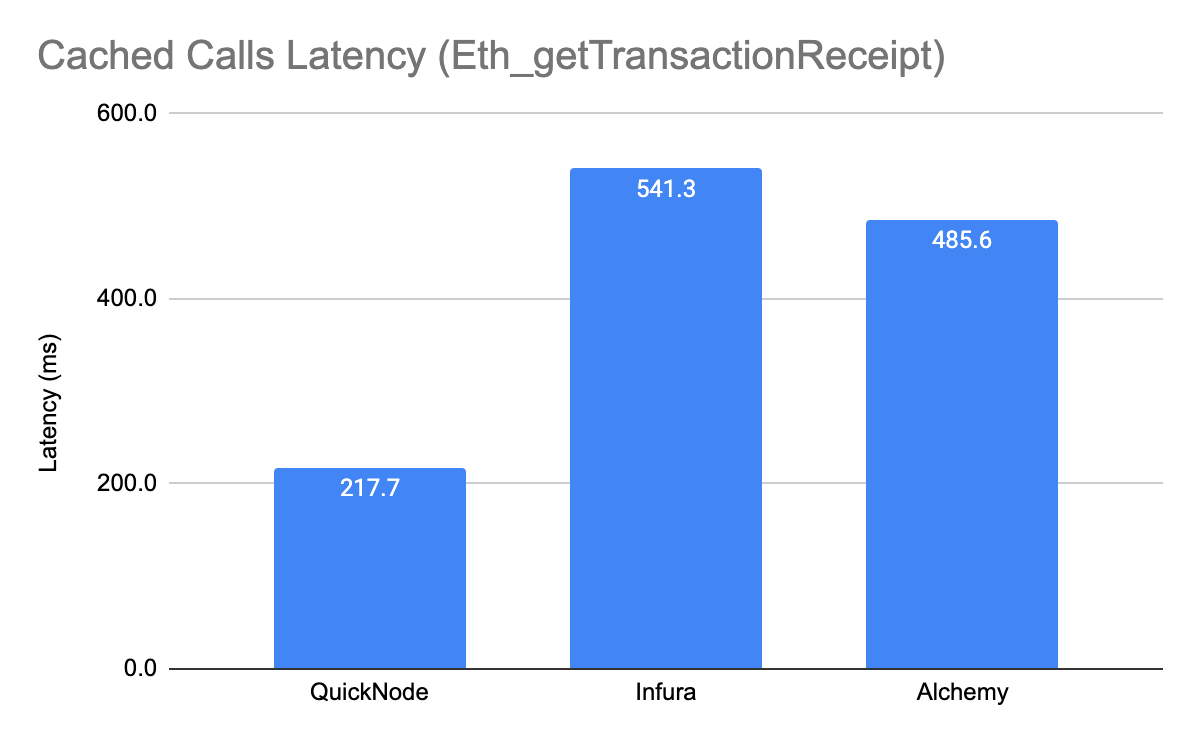
Cached Calls (Eth_getTransactionReceipt)
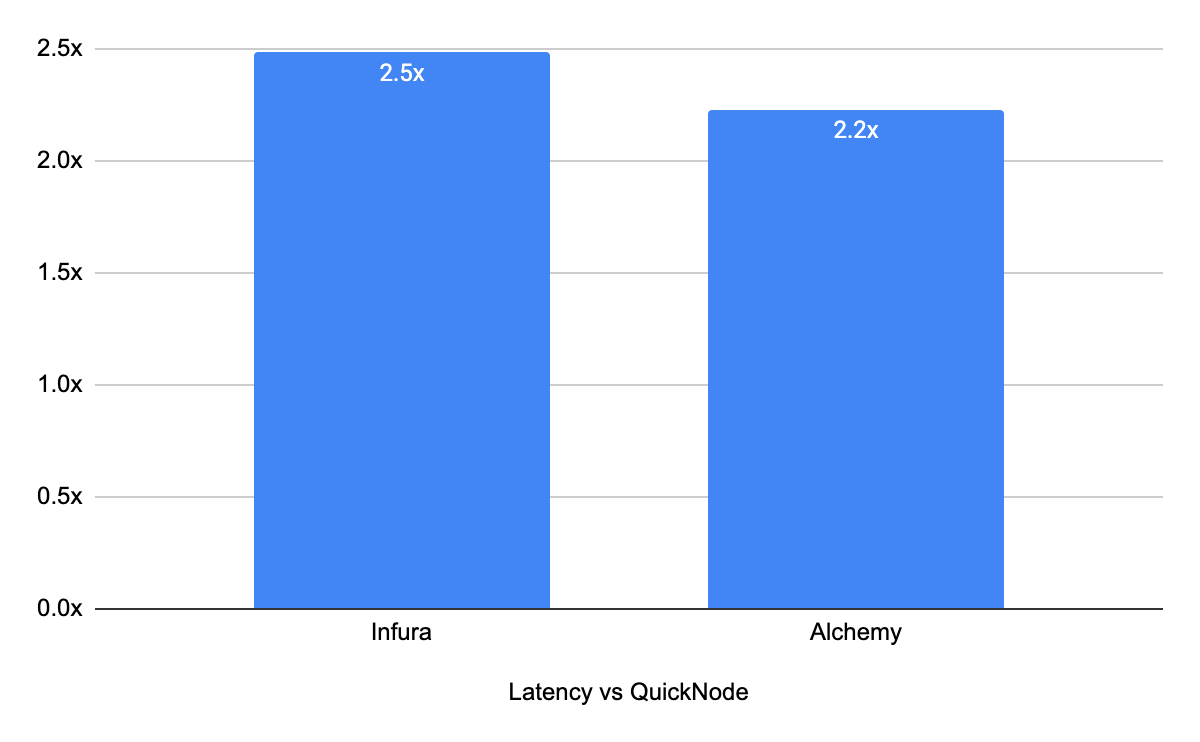
When looking at latency, the average response time for the QuickNode network was 217.7 ms. For Infura, the average latency over the 28 day period was 541.3 ms (2.5x difference) and for Alchemy the average latency was 485.6ms (2.2x difference)
On average, the difference in latency between QuickNode and the other two providers was 2.4x for cached calls.
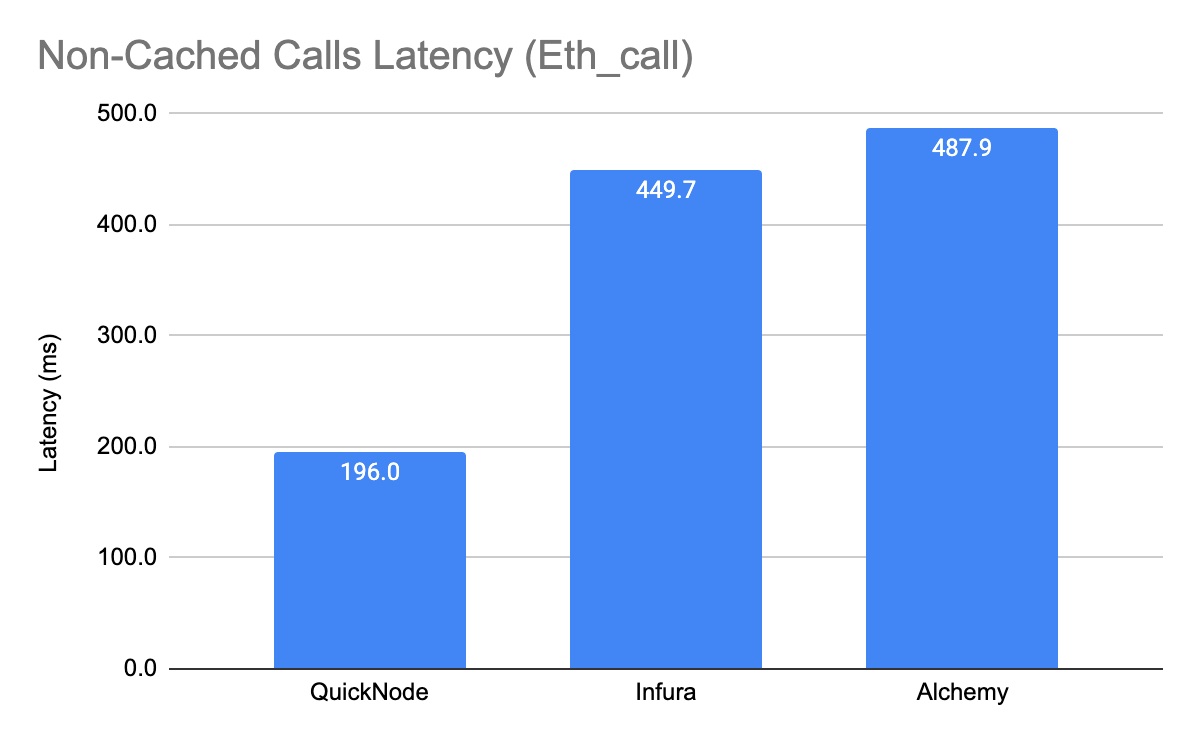
Non-Cached Calls (Eth_call)
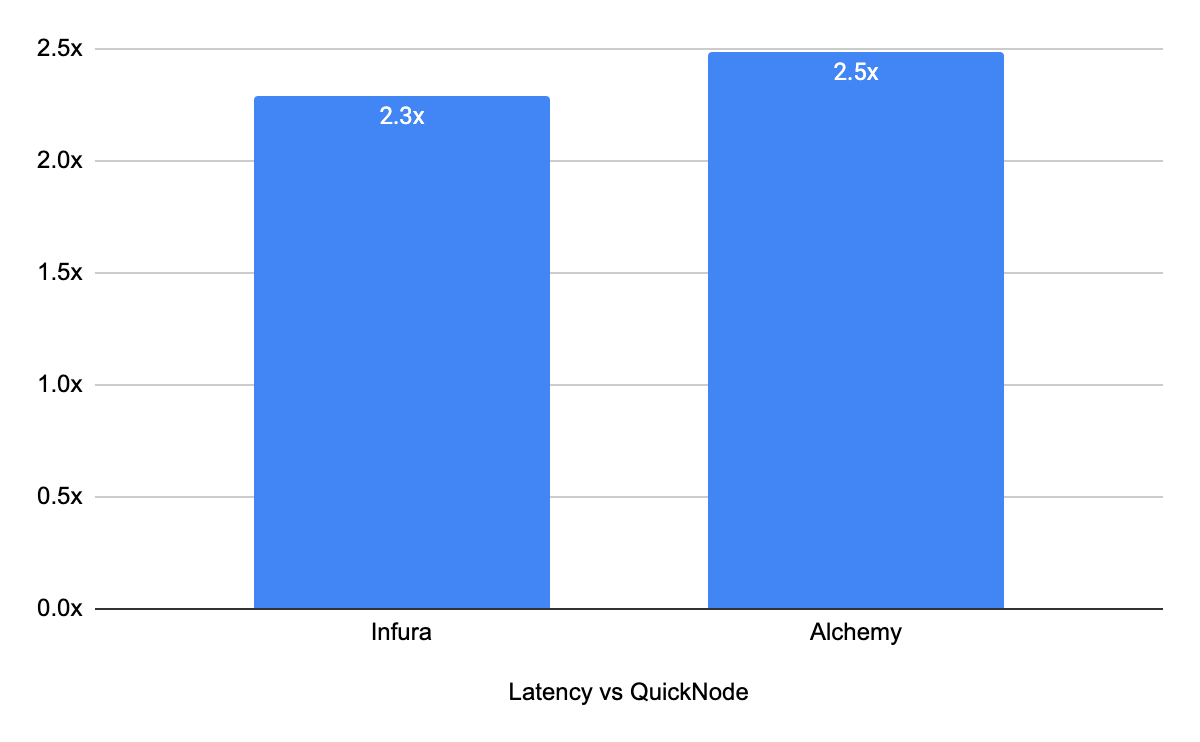
When looking at latency for Non-Cached calls, the average response time for the QuickNode network was 196.0 ms over the 28 day study period. For Infura, the average latency over the 28 day period was 449.7 ms (2.2x difference) and for Alchemy the average latency was 487.9ms (2.5x difference)
On average, the difference in latency between QuickNode and the other two providers was 2.4x.
Conclusions
Transparency matters and developers should have access to the best data in choosing blockchain infrastructure. And thinking about options with a focus on latency is important for any developer that is focused on the user experience. We hope this study can help people in making better-informed decisions, and similar to our previous whitepaper, we are sharing our methodology so others can build on what we are publishing.
Appendix
The test can be replicated using: https://docs.datadoghq.com/synthetics/
Why QuickNode?
QuickNode makes running Blockchain nodes easy so developers can focus on the dApps they’re building, instead of worrying about DevOps/NodeOps, uptime, scaling, security, etc.
QuickNode saves valuable time getting to-market while taking away the headache of node maintenance and synchronization. It’s a valuable tool in every dApp developer’s arsenal that was created by developers for developers. Visit QuickNode’s Guides section for more information.
Today, the QuickNode network processes over 50 Billion requests per month, from over 10 regions worldwide!
Need help with your project or have questions? Contact us via this form, on Twitter @QuickNode, or ping us on Discord!
About QuickNode
QuickNode is building infrastructure to support the future of Web3. Since 2017, we’ve worked with hundreds of developers and companies, helping scale dApps and providing high-performance access to 16+ blockchains. Subscribe to our newsletter for more content like this and stay in the loop with what’s happening in Web3! 😃



