Mastering Web3 Data With Blockchain ETL — Streams, Filters, Functions
Managing blockchain data is complex, but QuickNode simplifies the process with its comprehensive ETL suite: Streams, Filters, and Functions.


If you're building decentralized applications (dApps) or a blockchain-based solution, the last thing you want to focus on is to bootstrap sourcing of blockchain data and employing the data for your dApp functionality. The process is unnecessarily complex and involves multiple ETL (Extract, Transform, Load) steps.
Whether you're merely tracking transactions or monitoring smart contracts, the challenges are significant, like that of manual polling, error handling, and retries.
Let’s face it: Handling blockchain data is no mere feat.
We know that you need blockchain data to power your dApp, but the complexity of building and maintaining a reliable data pipeline should never slow you down.
This blog helps you realize the true headache of blockchain data management, and how QuickNode's suite of tools — Streams, Filters, and Functions — addresses these challenges and streamlines your blockchain data workflow.
Key Challenges of Web3 Data and Blockchain ETL
Blockchain data management is a hassle, yes, but how exactly?
From self-validating and indexing blockchain data to adapting to chain reorgs (reorganizations), data management in web3 is super complex for the majority.
Here are five prime challenges that you’re likely to face while working with blockchain data:
- Inefficient data ingestion: Traditional JSON-RPC methods involve resource-heavy polling, retries, and error handling, making web3 data ingestion inefficient and a nightmare for developers.
- Scalability challenges: Handling large volumes of blockchain data in real-time is difficult with traditional methods, causing bottlenecks and performance issues in dApps.
- Inconsistent data delivery: Chain reorganizations and network delays can lead to missing or corrupt data which are further delivered unpredictably.
- Cost of data overload: Without filtering, developers incur high costs by receiving and processing large volumes of irrelevant blockchain data, wasting resources.
- Inability to modify data payload: Standard pipelines lack pre-destination filtering and customization. This means additional post-processing is required, increasing complexity for developers.
Despite all these, blockchain data is pretty manageable with the right infra, and for most web3 use cases, QuickNode’s ETL suite of Streams, Filters, and Functions is the perfect fit. Let’s understand each of the solutions in detail to know what painpoints they specifically fix and how best to extract value from them.
Streams: Powerful Real-Time Data Pipelines
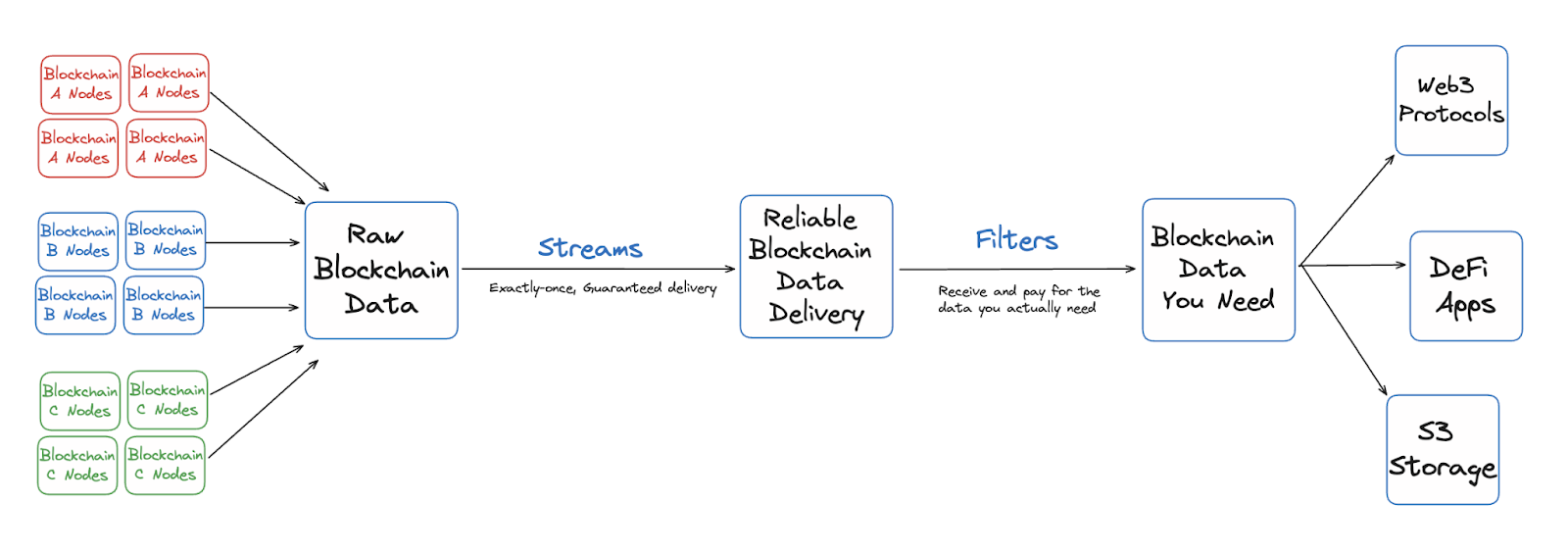
Streams is a real-time blockchain data solution designed to simplify and optimize data pipelines for dApps. It pushes blockchain data directly to your preferred destination in real time. It solves pain points like high resource consumption, scalability challenges, and inconsistent data delivery.
Simply put, Streams is a feature that allows developers to subscribe to real-time blockchain events.
With Streams, you can monitor the blockchain for specific types of data or activity, such as:
- Transaction activity: Subscribe to transactions on a specific address, contract, or across the entire network.
- Smart contract events: Monitor specific events emitted by smart contracts, such as when a token is transferred or when a specific function is called.
- Block changes: Track when new blocks are added to the blockchain, and extract relevant data as needed.
This way, Streams for developers means less complexity, reduced costs, and more reliable data delivery for their dApps, including automatically scaling infra.

Real-Time Blockchain Data Made Easy With Streams
QuickNode Streams effectively is the blockchain data infrastructure that dApps require to be more responsive, latency-free, and consistent.
Here are five features of Streams that streamline blockchain data pipelines:
- Real-time data delivery
Push-based data flow ensures you receive blockchain data instantly, eliminating the need for constant polling and manual checks.
- Scalable infrastructure
Streams automatically scale with your needs, handling large volumes of data without performance bottlenecks or delays.
- Guaranteed data
Streams guarantee data is delivered exactly once, in the order of on-chain finality, preventing data loss or duplication.
- Seamless integration
Easily connect Streams to various destinations like Webhooks or S3, with just a few clicks, simplifying your data ingestion process.
- Historical data handling
Configure and backfill historical data with complete accuracy, ensuring your dApp has access to all the data required for its functioning.
How QuickNode Streams Works?
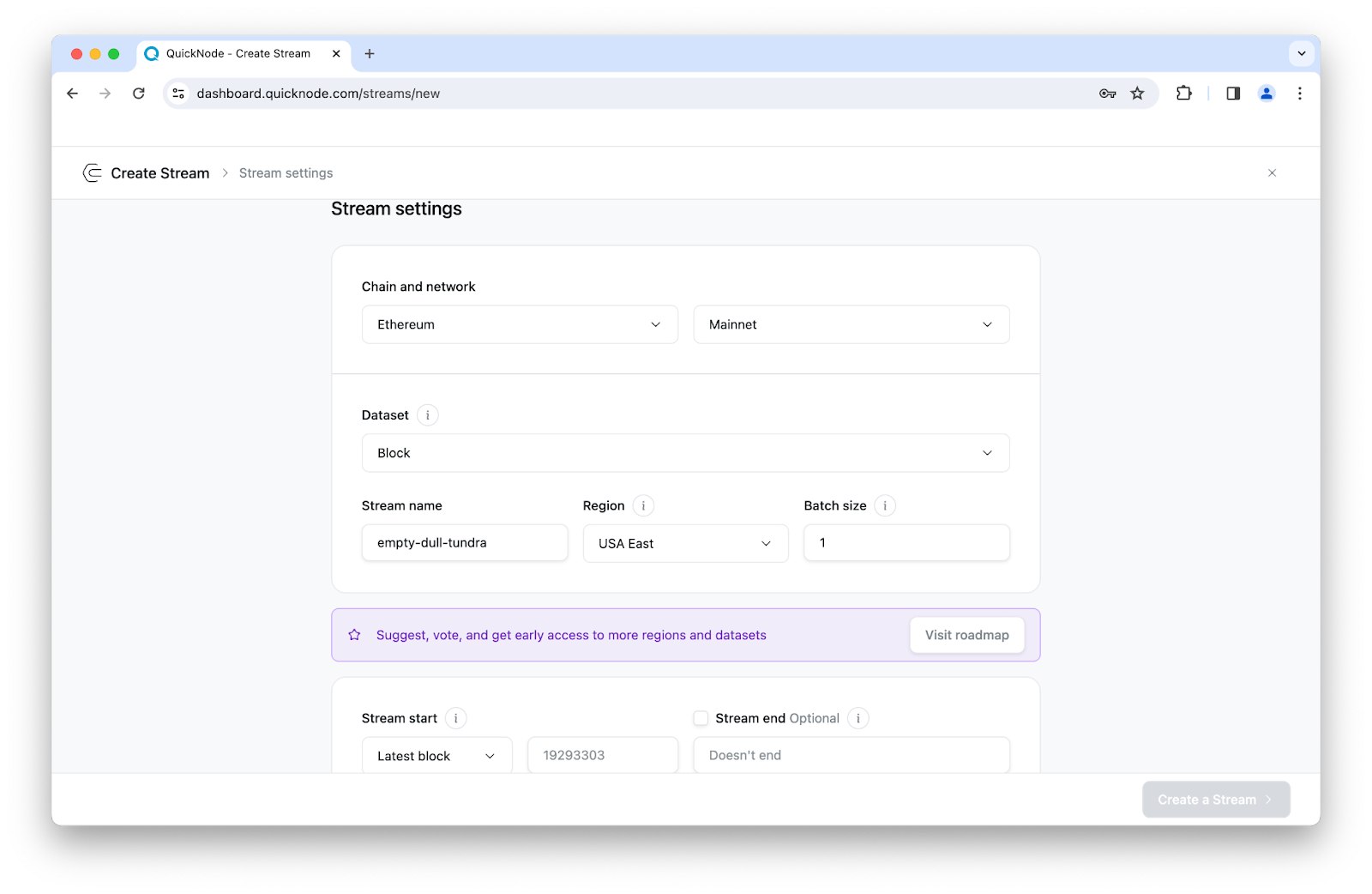
Step 1: Configure stream settings
Select your blockchain network, define batch size, set date ranges, and configure reorg handling.
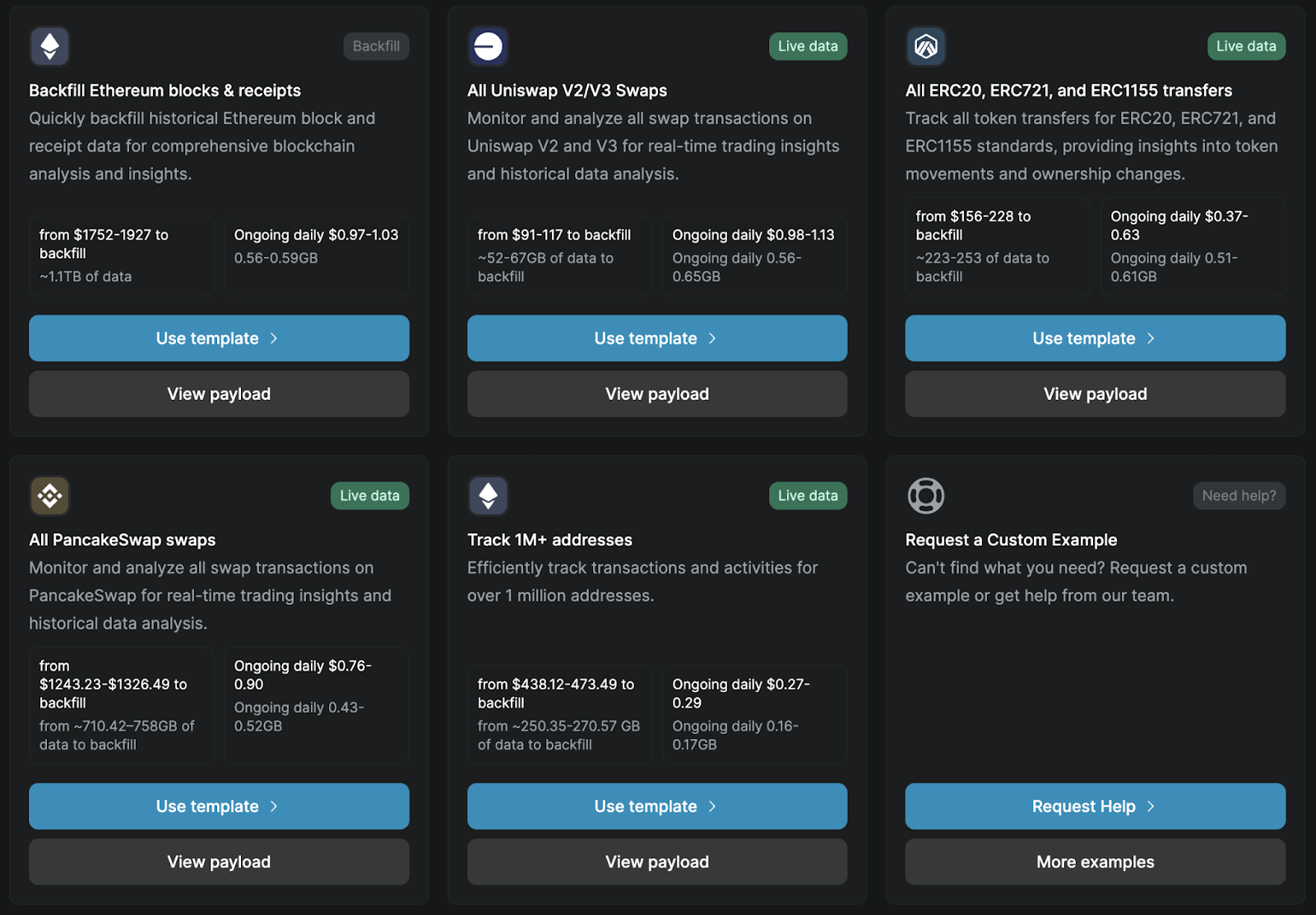
Step 2: Apply filters
Customize your data stream by applying filters to receive only relevant data, reducing unnecessary transmission.
Step 3: Connect to a destination
Streams push the filtered data to your chosen destination, ensuring exact-once delivery with real-time consistency.
Step 4: Monitor and manage
Use the Streams dashboard to track performance, view logs, and manage stream configurations, ensuring transparency and control.
Streams enable developers to react immediately to blockchain events. This is a crucial task for applications that require up-to-the-minute data, such as decentralized exchanges (DEXs), NFT marketplaces, or any dApp that depends on real-time blockchain activity.
Now that we have access to reliable data, let’s delve more into the specificity of data i.e. sourcing only the needed data from the ledger.
Filters: Customized and Relevant Data
Filters help refine and customize the data you receive from Streams. It allows developers to apply JavaScript (ECMAScript) code i.e. custom filter functions to modify data payloads from the incoming blockchain data. This ensures developers only process and pay for the data they need.
Custom filters solve the pain points of processing irrelevant data, high costs due to unnecessary data ingestion, and the need for custom data processing logic.
Relevant Blockchain Data Only with Filters
With Filters, developers gain control over the data they receive, effectively leading to cost-effective workflows and an efficient data pipeline.
The three backbones of Filters are:
- Customizable filtering
Write JavaScript functions to filter blockchain data streams, receiving only the data you need, reducing overhead.
- Easy implementation
Filters can be easily configured through the QuickNode developer portal or via the Streams REST API, ensuring smooth implementation.
- Key-value store access
Utilize the Key-Value Store within Filters to create lists, update sets, and enhance data processing with stored values.
How QuickNode Filters Works?
Step 1: Define your filter function
Use JavaScript (ECMAScript) to write a custom filter function named 'main' substituted by the following filters like:
- streamData,
- streamName,
- streamRegion,
- streamNetwork, or
- streamDataset
Step 2: Configure in Streams
Apply your custom filter to a Stream either through the QuickNode developer portal or the Streams REST API.
Step 3: Receive filtered data
Your chosen destination receives only the data that passes through your filter, optimized for your specific needs.
Also, use the QuickNode dashboard to monitor the performance of your filters and make adjustments as needed for further optimization.
Filters help reduce the noise and only surface the data that matters to your application.
Now that we have narrowed down the blockchain data to receive only what data we need, we can focus on executing custom logic on the data as it streams in.
Functions: Serverless Edge Functions for Blockchain Data
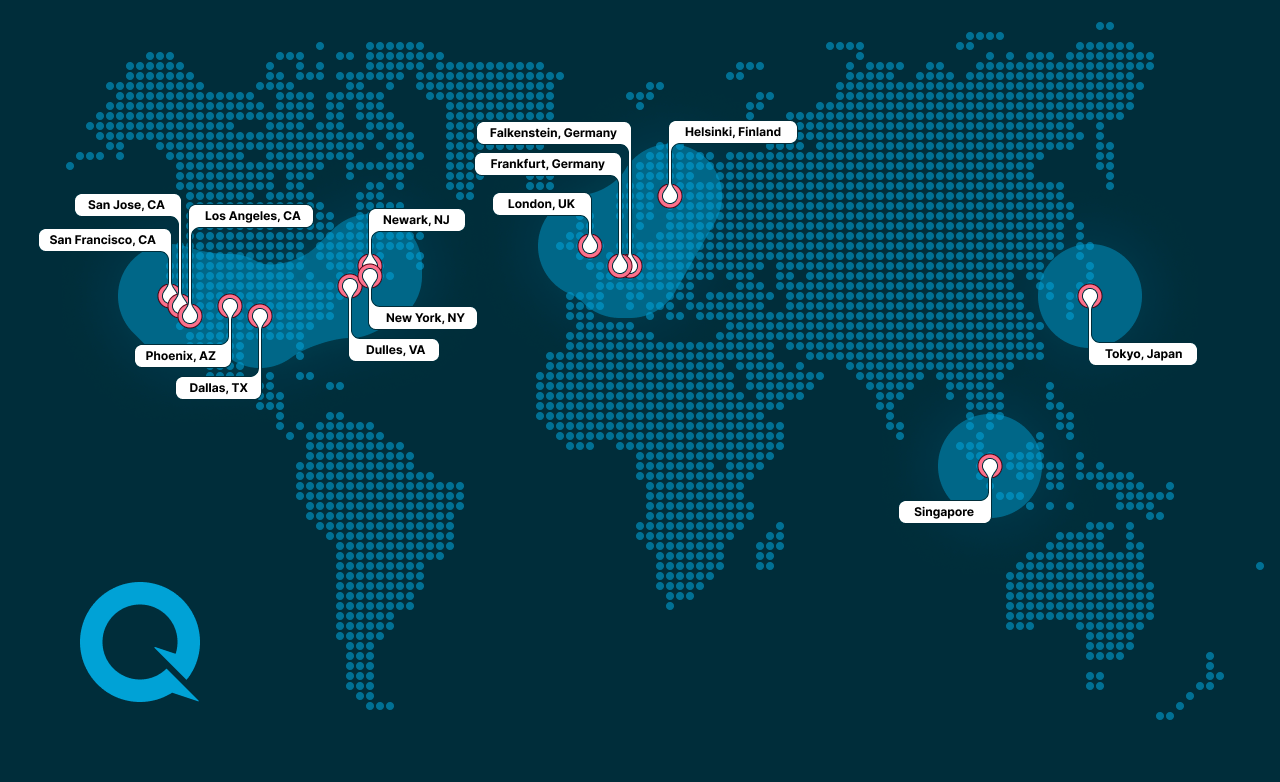
Functions is a serverless computing platform optimized for blockchain data. It allows developers to deploy lightweight, scalable code closer to the user, enhancing performance and reducing latency.
This solves critical pain points such as:
- Infrastructural overhead: Eliminates the need for maintaining servers and the technical components required for computing.
- Complex data operations: Perform real-time filtering, transformation, and enrichment of blockchain data without relying on external systems.
- Scalability and performance: Automatically scale to meet demand, ensuring smooth operation even during peak loads.
For developers, Functions offers a powerful way to extend dApp capabilities, process blockchain data efficiently, and reduce operational complexity.
Execute custom logic on real-time blockchain data using Functions
Functions provide a serverless, blockchain-optimized compute layer that complements Streams and Filters.
Here are the five key features of this layer:
- Edge deployment
Deploy your code closer to blockchain data for quicker execution, reduced latency, and improved responsiveness and performance for dApps.
- Serverless and scalable
Functions handle the scaling and management automatically to meet demand, eliminating the need for manual infrastructure oversight.
- Cost-effective computing
Pay only for the compute you use with a transparent pricing model, ensuring that your resources are optimized and costs are predictable.
- API-Ready
Functions are automatically exposed as APIs, ready to be integrated with your front-end, services, or as destinations for Streams.
- Streams integration
Use Functions as a destination for Streams, automatically sourcing, filtering, and transforming blockchain data on the fly within a single workflow.
How QuickNode Functions Works?
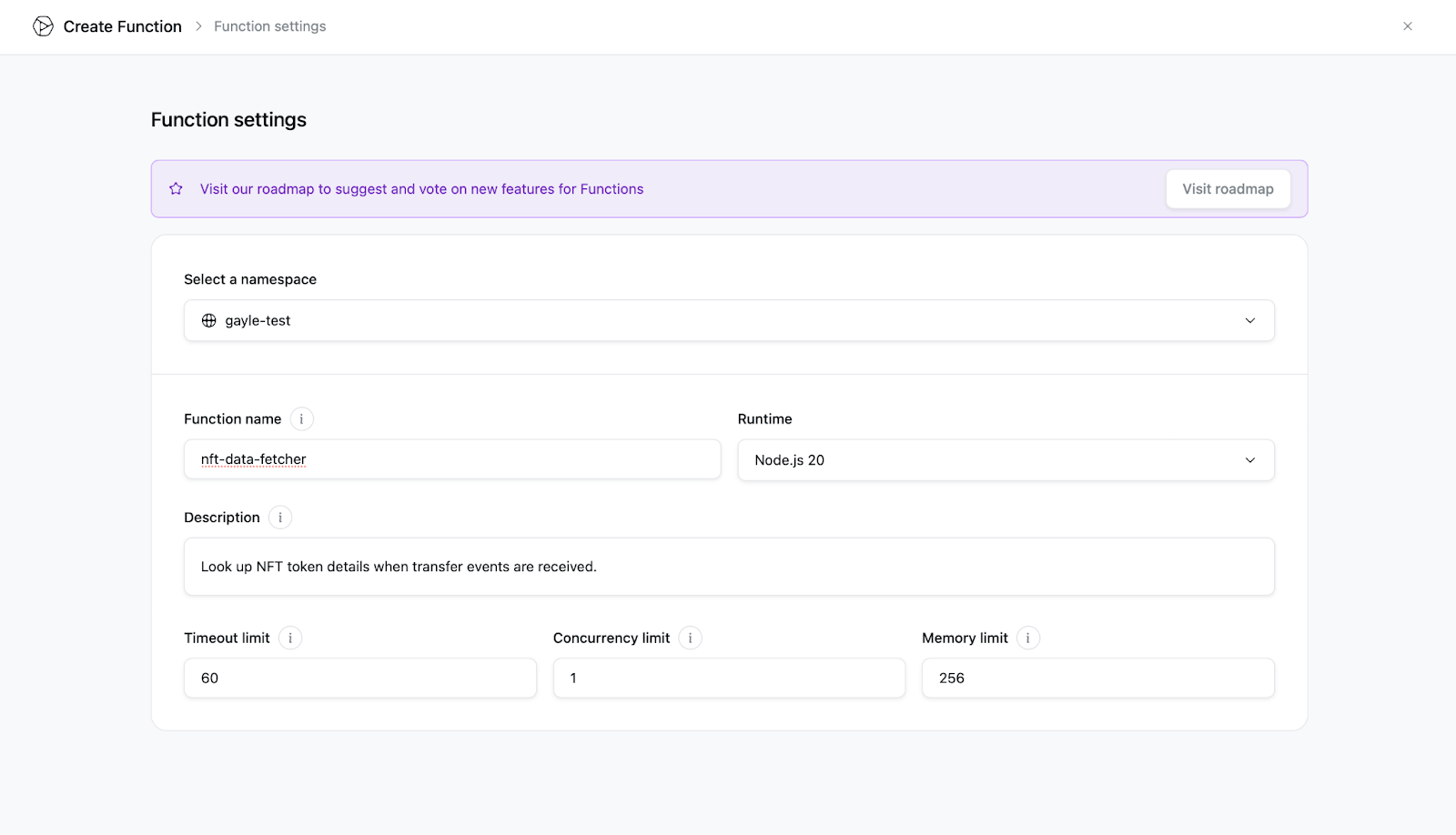
Step 1: Write your function
Develop your function code using supported languages (e.g., Node.js, Python) with built-in access to common web3 packages.
Step 2: Deploy to the edge
Set up your function as a destination for Streams and deploy your function to QuickNode's edge infrastructure, ensuring it runs close to the data source.
Step 3: Configure triggers
Set up your function to automatically respond to API calls, Streams data, or other scheduled events.
Step 4: Execute and scale
Track performance, scale automatically with demand, and adjust configurations via the QuickNode dashboard.
Overcome Web3 Data Challenges with QuickNode ETL Solutions
This blog covers how QuickNode has built a holistic suite of blockchain data solutions to help developers and web3 projects fix their data gaps. Streams, Filters, and Functions essentially work together to streamline how dApps and DeFi protocols access, interact, and function with blockchain data.
Together, they simplify real-time data ingestion, enable precise filtering, and allow custom data processing, all without the overhead of managing infrastructure.
Contact us to learn more about how we can help you set up the best blockchain data infrastructure for your dApp or web3 project.

About QuickNode
QuickNode is building infrastructure to support the future of Web3. Since 2017, we've worked with hundreds of developers and companies, helping scale dApps and providing high-performance access to 40+ blockchains. Subscribe to our newsletter for more content like this, and stay in the loop with what's happening in web3!